進行機器學習的模型建立前,了解一下我們手中的資料是必要的過程,所以今天來講一下「探索式資料分析(EDA)」。
在開始機器學習前,我們先來看看資料分析的基本流程: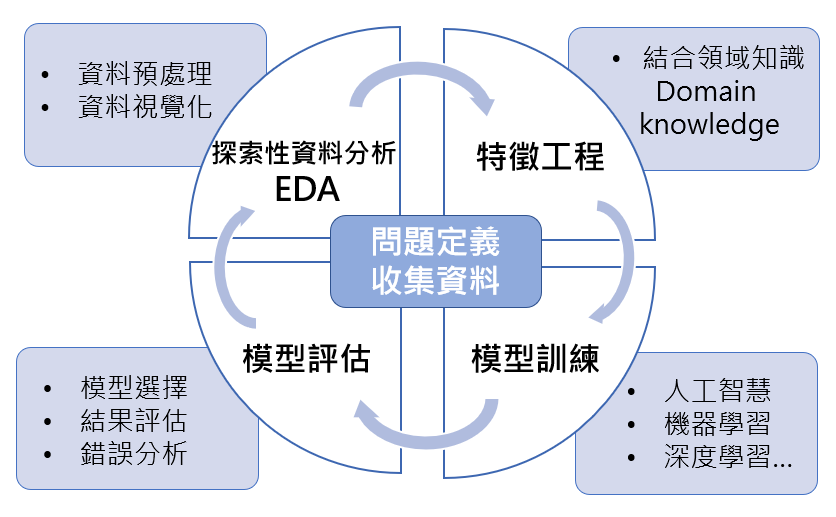
在進行資料分析前,首先需要做的就是確認問題,訂定好我們的目標(Target, Y),然後才去收集資料,拿到資料後才開始我們的資料分析流程。
拿到新的資料時,我們一定要去做探索式資料分析,並看看資料的型態或是資料集中有沒有不尋常的數值出現。做探索式資料分析時,通常會從「敘述統計」或是「視覺化資料」先下手。
敘述統計就是直接去陳述資料或變數的統計量,以下是我在做敘述統計時常用的R指令:
看資料的整體:
| 指令 | code |
|---|---|
| 整體摘要 | summary( ) |
| 每個欄位的狀態 | str( ) |
| 前6筆資料 | head( ) |
| 資料筆數 | nrow( ) |
| 變數(欄位)數目 | ncol( ) |
| 變數型態 | class( ) |
| 變數各個值的分布 | table( ) |
數值統計:
| 指令 | code |
|---|---|
| 平均 | mean( ) |
| 中位數 | median( ) |
| 變異數 | var( ) |
| 標準差 | sd( ) |
| 最小值 | min( ) |
| 最大值 | max( ) |
| 四分位數 | quantile(x,c=(0.25,0.5,0.75)) |
| 全距 | range( ) |
| 百分位數 | quantile(x,c=(0.5)),0.5可以換成其他百分位 |
| 共變異數 | cov(x1, x2) |
| 相關係數 | cor(x1, x2) |
補充:
計算平均時,若有遺失值,可以使用mean(na.omit())忽略遺失值進行計算。
計算相關係數時,根據變數的特性,可以選擇不同方式進行相關係數的計算,預設為cor(x1, x2, method = pearson),其他方法包含 method = pearson, kendall, spearman。
這邊再介紹一個很方便的packageskimr,package裡的skim( )函式會一次整理出資料集的統計資訊:
install.packages("skimr")
library(skimr)
skim(data) # data代入你的資料
以Iris data為例:
library(skimr)
skim(iris)
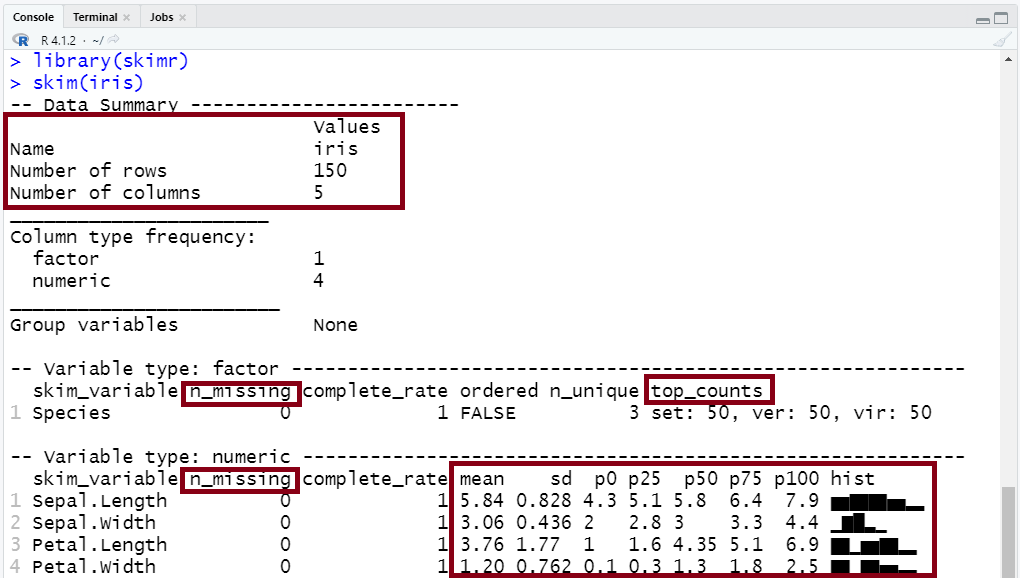
從 Console 的結果由上而下依序來看,我們可能會去注意看資料的:
在資料視覺化的過程中,我們可能就已經能從資料中得到許多的資訊,包括:
資料視覺化的相關筆記預計在別天做更詳細的補充,以下先提供幾種內建基礎的資料視覺化程式碼。
| 指令 | code |
|---|---|
| 直方圖 Histogram | hist(x) |
| 長條圖 Bar chart | barplot(height), barplot(table(x)) |
| 圓餅圖 Pie chart | pie(x) |
| 散布圖 Scatter plot | plot(x, y) |
| 散布圖矩陣 scatter-plot matrices(SPLOM) | pairs(data) |
| 盒鬚圖Box plot | boxplot(x) |
| 莖葉圖Steam-and-leaf plot | stem(x) |
以Iris data為示範:
data(iris)
summary(iris)# 連續型資料:會看到 Qu. #類別型資料:會看到不同類別的資料個數
head(iris) # 觀看前6筆資料
str(iris) # 列出資料內每個欄位的狀態
class(iris$Species)
table(iris$Species) # 不同種類各有多少筆資料
hist(iris$Sepal.Length)
barplot(table(iris$Species))
pie(table(iris$Species))
plot(iris$Sepal.Length,iris$Petal.Length)
boxplot(iris$Sepal.Length)
stem(iris$Sepal.Length)
##補充
#另一種方便的barplot繪圖方式
library(lattice)
barchart(iris$Species)
補充:
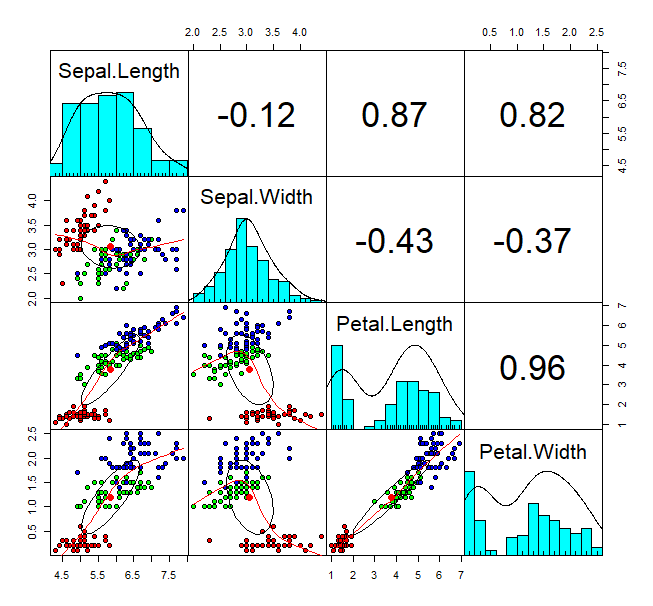
畫畫看散布圖矩陣(SPLOM):
# 進階: 畫出前四項變數的scatter diagram, histogram, & correlation values
install.packages("psych")
library(psych)
data(iris)
pairs.panels(iris[1:4],
gap = 0, #圖與圖之間的空隙
bg = c("red", "green", "blue")[iris$Species],#將樣本根據Species分別套色
pch = 21) #pch 點的圖形
Describing Datasets
https://medium.com/@amanann/describing-datasets-76b221d7d517
探索式資料分析如何做? (@Tony Lee)
https://www.sightingdata.com/post/how-to-do-eda/

